 |
We fielded several questions as part of our recent webinar (recording and slides available here): What are Knowledge Graphs? Why are they Important for Data Governance? |
Questions from the webinar included:
Q1: Can we manage discrete separate knowledge graphs?
Yes, each asset collection is created as its own graph e.g., a specific glossary. You can then flexibly include these collections/graphs into each other, creating larger assemblies of graphs.
Q2: Do you have a way to select one of the vocabulary terms from the different sources as a “preferred term” within the context of the enterprise?
We see this as possible additional metadata on the terms. There is a pre-built property for Terms that is called “used by organization”. It could be used to indicate that what group within enterprise a specific term is used by, e.g., used by the sales department, support department, etc. For example, we could have said that “Client” from the ITIL glossary was used by the “Information Technology Division” and “Client” from the SEC glossary was used by the “Investment Services”.
This property could potentially be used to say “Enterprise-wide” – meaning that this is the preferred term. Or an additional property can be created as a Boolean to indicate if the term is preferred in the enterprise. Preference can also be contextual, so this may require an additional structure to capture it. With EDG, users can freely extend the underlying models to suit their needs.
Q3: When was the term ‘knowledge graph’ coined or introduced? Any idea of the first usage of the term?
We believe that Google first used the term in 2012, specifically to describe their knowledge base. Today, this term and the related term “Enterprise Knowledge Graph” are used to describe an interconnected (linked) set of information that meaningfully brings together data and metadata silos. For more information on Knowledge Graphs, take a look at this white paper.
Q4: Is client always a Person? Party? Role?
It is up to each enterprise and/or a group in the enterprise to define what they may mean by the term Client. In the example we used from ITIL , client is defined as “A generic term that means a Customer, the Business or a Business Customer.” US Security and Exchange Commission defines client as “Any of your firm’s investment advisory clients. This term includes clients from which your firm receives no compensation, such as family members of your supervised persons. If your firm also provides other services (e.g., accounting services), this term does not include clients that are not investment advisory clients”.
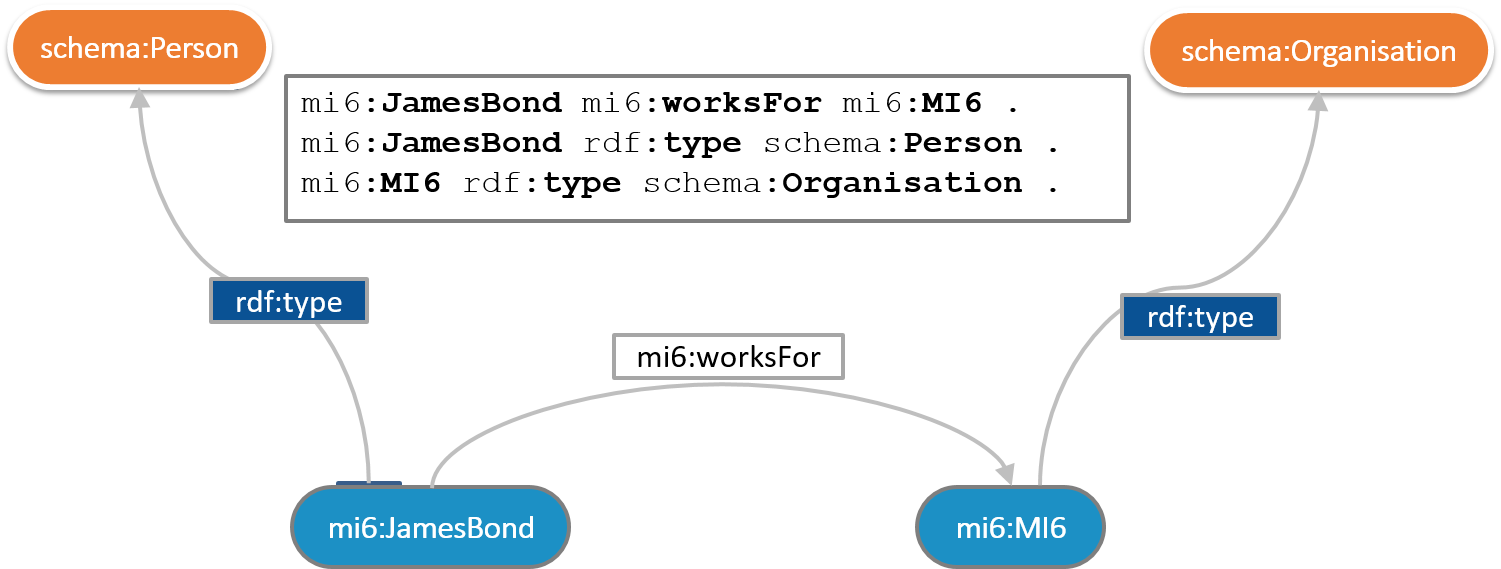
Human language is highly contextual and often the same word is used to mean different things. In the EDG knowledge graph, we use RDF data model and standard where each resource has a unique URI. Thus, identity and meaning of a resource are not determined by its label. There can be two or more different resources called “client” that mean different things and each will have its own unique, unambiguous identity. You could then specify how each of these resources relates to each other and to other things in your enterprise.
Q5: Who does the mapping between graphs? Can this be automated?
Mapping can be and is automated. For example:
• EDG automatically creates crosswalks between different taxonomies and ontologies and between private and public information such as Wikidata. Click here for example.
• It can also auto-map data elements to glossary terms based on rules that describe the meaning of a term. Click here for a demo.
Other types of reasoning could also be used to automate the mapping process.
Q6: How far would I be, from a correct understanding of TopBraid EDG, if I call it “real-time semantic enterprise data aggregator”?
EDG is semantic and it crosses silos of enterprise information.
Having said this, “real-time aggregation” of data from multiple sources may mean real-time answering of queries that require on-demand combining of information that lives in different sources. For example, a request for a 360-degree customer view where a system gets as input some info about a customer and needs to go to multiple databases, get information about this customer, merge it together and present it to the requestor. EDG “out of the box” is a data governance platform. It has data conversion to RDF capabilities, rules and workflows, so one could potentially use it to create a 360-degree view of a customer, but this would require system integration work.
Q7: Does the “edg” namespace contain the key Classes and Properties that EDG provides? Are there any other edg-related namespaces?
Yes, correct.
EDG also uses SKOS for Taxonomies. RDFS, SHACL and OWL are used for ontologies.
There are some “utility” models in the server.topbraidlive.org project, especially under /dynamic folder in this project. Also in the TopBraid project – for example, under /TBC folder there are models used to support conversion from different formats to RDF.
Q8: No exports to OWL?
All information in EDG knowledge graph is stored as RDF. Information can be exported in one of standard RDF serializations of user’s choice.
In the webinar, we have been using mostly RDF data and only showed ontologies tangentially. TopBraid EDG supports OWL. OWL is defined in RDF. Thus, one could have OWL ontology in EDG and export its RDF serialization. Having said this, for a variety of reasons, we are increasingly using W3C standard SHACL for modeling and offer a transformer from OWL to SHACL.
In this webinar we only showed a small percentage of EDG capabilities. There is a number of Export options ranging from exporting each graph or a set of graphs in RDF to highly focused exports of subset of graph information. The latter options are typically results of queries and are commonly exported as either JSON (using GraphQL) or tabular resultsets (using SPARQL).
Q9: Can temporal effectivity be stated on a term or relation?
Terms and most other EDG assets have pre-built metadata for effective start and end dates. These are defined in the ontologies underlying TopBraid EDG. EDG is fully model driven and additional properties can be defined by users as/if needed. Pre-built properties can be deactivated.
Adding temporal effectivity to a relationship requires reifying a relationship. EDG provides support for this as well.
Q10: There have been different senses of the term used, e.g., interchangeably with ‘ontology’. How would you describe a knowledge graph as distinct from an ontology? For example, when developing an ontology in TopBraid Composer or in Protege, one can have class-level term, but also instance-level. The so-called instance graph can be found in an ontology built in Protege by asserting instances and relations between the instances or b/w instances and classes (types). So how would you say (if at all) that ontology product different from a knowledge graph?
TopBraid EDG lets you work with ontologies (classes and properties) and data based on these ontologies. One of the key advantages of using RDF and associated languages for knowledge graphs is that models and rules are just as much a part of the knowledge graph as the data facts. They are not maintained separately in some programs. We advocate separating schema sub-graphs from data sub-graphs as a best practice – while keeping them connected in the overall knowledge graph. EDG facilitates, but not mandates this separation.
If you are, on the other hand, asking how EDG is different from Protégé, there are many differences. EDG is a highly scalable, enterprise-grade server product with role-based access control and workflows. EDG packages a scalable RDF store and stores data in RDF while Protégé does not and does not fully support RDF. EDG has a lot of features not present in Protégé – support for SHACL, GraphQL, data ingestion from many sources – to name just a few. Further, EDG focuses on governance of information and offers functionality targeted to governance use cases e.g., data lineage.
Q11: Can EDG be offered as a Cloud Service?
Yes, some of our customers run EDG on AWS, Azure or a private cloud.
Q12: How do taxonomies relate to or fit into knowledge graphs? How do ontologies related to or fit into knowledge graphs?
EDG treats all information it manages as part of a knowledge graph. We agree that some graphs are different from other graphs. This is why EDG supports the concept of an “asset collection type” or a “graph type”.
Taxonomies and Ontologies are types of graphs in EDG. EDG offers some specialized capabilities for certain graph types. For example:
• For data asset collections (AKA data dictionaries) there are import capabilities for ingesting DDL and for connecting to the source via JDBC to ingest metadata and do profiling. Such imports would not make sense for a taxonomy.
• For taxonomies, on the other hand, there is an import from MultiTes – a tool that is used for managing taxonomies. Such import would not make sense in a context of data assets.
Ontologies are quite special in EDG because they define the underlying models for data that is part of the knowledge graph. They are used to richly define the meaning of the data facts. An ontology may define that Geopolitical Regions contain Countries. Each country has one or more official languages and it has a single ISO alpha-2 country code. Countries have ‘capital’ relationship to Cities. And so on. A taxonomy may contain a hierarchical breakdown of regions, countries, and cities with some cities identified as the capital of each country. It can contain some other facts defined by the model – such as official languages for a country, its ISO code, etc. Both, the ontology and the taxonomy would be a part of a knowledge graph. Other information can also be a part of the knowledge graph – connecting and referring to the information in the ontology or taxonomy. For example, a dataset containing trading agreements between different countries.
Q13: Irene, can you demo a SPARQL query on the graph? (does it support geosparql?)
Sorry, we were not able to demo SPARQL in this session. You can request a private EDG demo by writing to edg-info@topquadrant.com. You can also request EDG evaluation account using this form.
EDG supports SPARQL 1.1. It also supports incorporation of property functions and ships with many pre-built property functions. Users can add their own property function implementations. We have not done functions for GeoSPARQL yet, but this is definitely possible.
Q14: Can EDG be hooked up to python or R?
Yes, it can be.
For example, R has a SPARQL Package allows you to directly import results of SPARQL SELECT queries into the statistical environment of R. EDG provides a SPARQL endpoint. Python also has tools for working with SPARQL. R and Phython programs could also query GraphQL. EDG can generate any kind of exports, so there are options.
Q15: I see the value of knowledge graphs, but my company is small and doesn’t have the financial ability to build our own knowledge graph, can you suggest some alternative methods/solutions?
Depends on what are you wanting to accomplish – the specific value that you see for your company.
Q16: Does TopBraid EDG has all RDF db store and editor similar to Protege and also an inferencer engine?
Yes, TopBraid EDG packages a scalable RDF database. Information in it can be edited using any modern browser.
During the webinar, we have been showing RDF data in tables and in forms. These are editable views, provided that a user has the right permissions. Any value can be edited and new values can be added. While we did not show in this webinar creation of classes, properties, etc., this capability is certainly there. If interested, you can take a look at one of our videos. Inferencing capabilities are also provided through rules and integration of machine learning.
Q17: Also what offerings from TopBraid are available as SAAS or PAAS models on the cloud as pay per use options?
TopBraid EDG can be hosted on a public cloud (e.g., AWS) or a private cloud. TopQuadrant offers either perpetual licenses or subscription licenses. Minimum duration of a subscription is 1 year.
Q18: Does the TopBraid Composer have any mechanism to determine that a specific TTL file is a glossary or taxonomy or crosswalk, etc? Or does it treat all the TTL files the same way?
TopBraid Composer does not distinguish between different graphs/files based on the content of a graph. It treats all files containing RDF serialized data the same way.
TopBraid EDG, on the other hand, has this distinction and provides different view/edit applications for different types of graphs (asset collections). It also provides, in some cases, different capabilities depending on the type of collection. For example:
• For data asset collections (AKA data dictionaries) there are import capabilities for ingesting DDL and for connecting to the source via JDBC to ingest metadata and do profiling. Such imports would not make sense for a taxonomy.
• For taxonomies, on the other hand, there is an import from MultiTes – a tool that is used for managing taxonomies. Such import would not make sense in a context of data assets.
Q19: Is there a good reason to store the data I have in a relational database in a graph database? When it becomes critical to have a graph instead of a relational database?
Yes, there are some good reasons to do so. Relational databases impose a very rigid data model that is expensive to evolve. One reason to move to a graph database would be because you need more flexibility than a relational database could provide. Another reason would be having highly networked relational data and needing for queries to extensively traverse the relationships. This works much better in a graph database than in a relational database. There are other reasons as well.