Using ADS from Node.js
This chapter explains how Active Data Shapes (ADS) can be used in Node.js applications. While ADS scripts typically execute on the TopBraid server (using the GraalVM engine), TopBraid makes it possible to generate a JavaScript/TypeScript file that can be used by apps running in Node.js. Such apps will under the hood communicate with TopBraid to answer queries and handle modifications. The use of ADS on Node.js combines the convenience of automatically generated ontology-specific APIs with the flexibility of the Node.js ecosystem. A major benefit of this architecture is that both the TopBraid server and the Node.js applications share the same APIs which allows applications to select whether an algorithm should execute on the client or on the server. To do so, Node.js applications can define JavaScript functions and dynamically install them on the server for execution, significantly reducing the required network traffic.
Active Data Shapes (ADS) technology defines a core JavaScript API (with classes such as NamedNode) and an API generator that takes SHACL shape definitions and generates additional ontology-specific classes such as skos_Concept.
TopBraid users can develop ADS scripts within EDG and store them as part of ontologies, e.g. to define additional actions and web services on resources in their models.
For example, ADS Web Services can be called from the outside and will execute on the TopBraid server.
From TopBraid 7.1 onwards, there is another way of using ADS scripts: executing them on a Node.js engine, as a so-called External Script. Such scripts have access to almost all features of ADS yet run separately, for example as microservice in a SaaS deployment. External Node.js scripts may access all features of the Node.js platform, and you may use any external tool to develop, test and deploy them. The following diagram illustrates the basic idea:
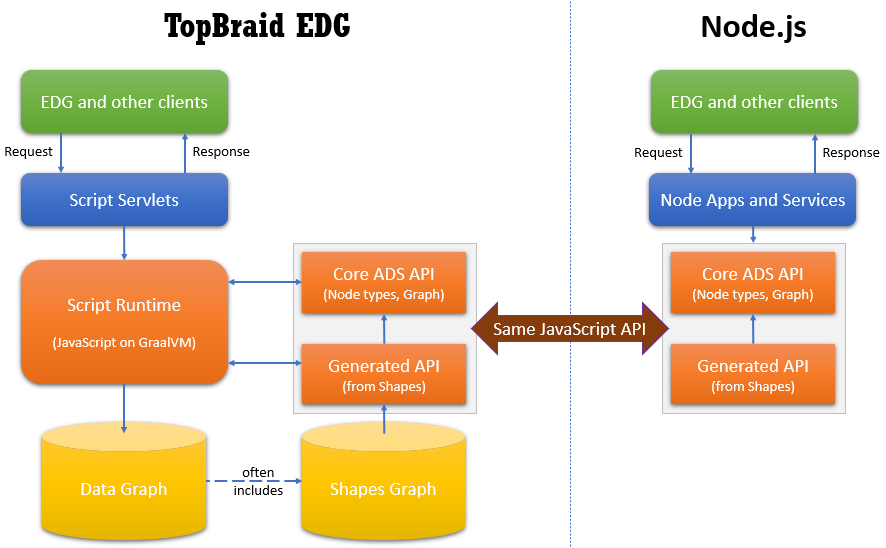
Getting Started
If you want to use this capability, you need Node.js version 12.3 or above. At the time of writing, it has been tested against version 14.17. It is recommended to use TypeScript to benefit from compile-time errors based on the type annotations in the ADS API, yet plain JavaScript will also work.
Assuming you want to write an ADS script for Node.js you first need to pick a target Ontology from EDG. On the Export tab of that Ontology, find the Generate JavaScript API for Node.js link and download the generated JavaScript file into your Node.js project.
For example, for the TopBraid Geography Example ontology, the resulting file would be called geography_ontology_ADS_generated_node.js.
This file contains the whole ADS Core API and the domain-specific generated API as well as some glue code.
External build systems may also periodically fetch this generated code through a web service, e.g. using tbl/generateScriptAPI/geography_ontology/node.
If you only need standard features supplied by EDG, such as just the SHACL or SKOS vocabularies, you can download one of the APIs for the system-provided standard shapes graphs by following the corresponding link from the Export section of any Ontology.
With this API file in your Node.js project, you can then create a .ts file and write code such as the following:
import { g, graph, TopBraid } from './geography_ontology_ADS_generated_node';
// Tell this script which TopBraid server to use
TopBraid.init({
serverURL: 'http://localhost:8083/tbl',
dataGraphId: 'geo',
langs: ['en', 'de'],
requestConfig: { // Optional, here for basic authentication
auth: {
username : 'admin',
password : 'password',
}
}});
try {
// Create a new g:City instance
let munich = g.createCity({
uri: 'http://example.org/Munich',
prefLabel: [
'Munich',
graph.langString('München', 'de')
],
areaKM: 100
});
// Print all cities
g.everyCity().forEach(city => console.log(`- ${city}`));
}
finally {
// Finish this TopBraid session with a message for the change history
TopBraid.terminate('Added a city');
}
An IDE may be used for developing and debugging:
An IDE such as VS Code can be used to edit ADS scripts that execute on Node.js
How does this work?
ADS is plain JavaScript, which of course also works on Node.js.
However, most API calls of the ADS API interact with the graphs stored in TopBraid.
When executing within EDG, ADS scripts have direct access to those graphs via the GraalVM engine’s ability to call Java functions from JavaScript code.
The generated API contains calls to a special ADS Session object (currently called __jenaData) for this bridge.
In order to make the same APIs work on Node.js, we merely had to implement this ADS Session object differently, so that it makes calls to a dedicated TopBraid servlet which then makes corresponding calls against the ADS Session object on the server.
In the following software component diagram, JavaScript code is in orange, and Java code (on TopBraid) in blue. You can ignore the left part which is about Using ADS from Web Applications and React.
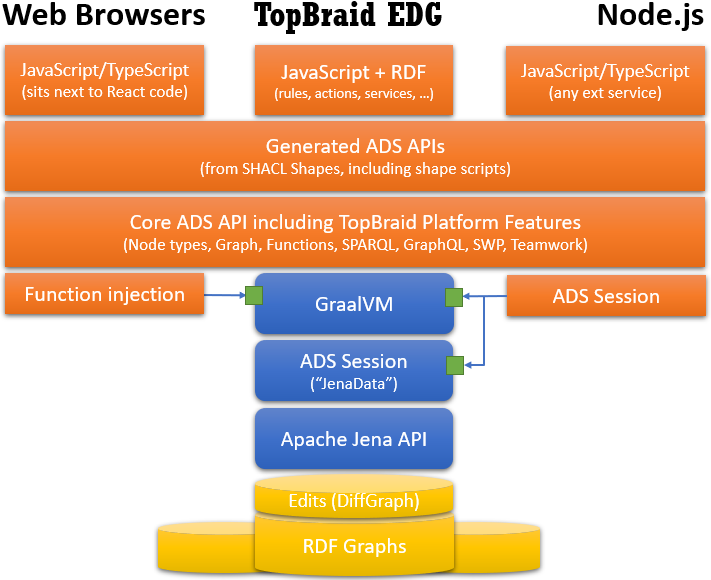
This design means that the same code will behave identically across the two platforms, yet both platforms have individual strengths and weaknesses. Most notably, the Node.js calls will create additional network traffic. Some strategies on how to avoid the performance impact of this traffic are covered in Performance Considerations. On the plus side though, Node.js code will likely run faster than corresponding GraalVM code, and you have more alternatives to exploit your hardware, for example through Node.js Worker threads.
Performance Considerations
ADS scripts executing on Node.js rely on network requests to fetch data from TopBraid.
For example, if your code is calling g.everyCity() it will under the covers make a servlet request against TopBraid to return a JSON array of cities.
Likewise even harmless-looking calls like console.log("" + city) will create network traffic because there is a hidden city.toString() in the code, which goes against the server to fetch the display label of the RDF resource.
Also all property accessors such as city.areaKM will cause small network requests.
As a running example, let’s assume we need to implement an algorithm that counts the total number of children of a skos:Concept, by recursively counting the narrower concepts.
A typical implementation of this in TypeScript against the ADS API would look at follows:
1const countChildren = (concept: skos_Concept): number => {
2 let count = 0;
3 concept.narrower.forEach(child => {
4 count += countChildren(child) + 1
5 })
6 return count;
7}
8
9console.log('Counting all children...');
10skos.everyConceptScheme().forEach(scheme => {
11 scheme.hasTopConcept.forEach(root => {
12 let childCount = countChildren(root);
13 console.log(`- ${root} has ${childCount} narrower concepts`);
14 })
15})
With the example loop above and TopBraid’s Geography example, this takes around 3 seconds to execute on Node.js, which is too slow for most real-world scenarios:
Counting all children...
- Asia has 141 narrower concepts
- Global has 19 narrower concepts
- Europe has 139 narrower concepts
- Atlantic Ocean has 11 narrower concepts
- Antarctica has 1 narrower concepts
- Africa has 102 narrower concepts
- West Indies has 43 narrower concepts
- North America has 411 narrower concepts
- Pacific Ocean has 53 narrower concepts
- Indian Ocean has 13 narrower concepts
- Latin America has 58 narrower concepts
Duration: 2957 ms
The reason why it’s slow is illustrated in the following swimlanes diagram. There is simply too much network traffic between the Node.js app and the TopBraid server, and this includes not just the network latency but also the overhead of JSON serialization.
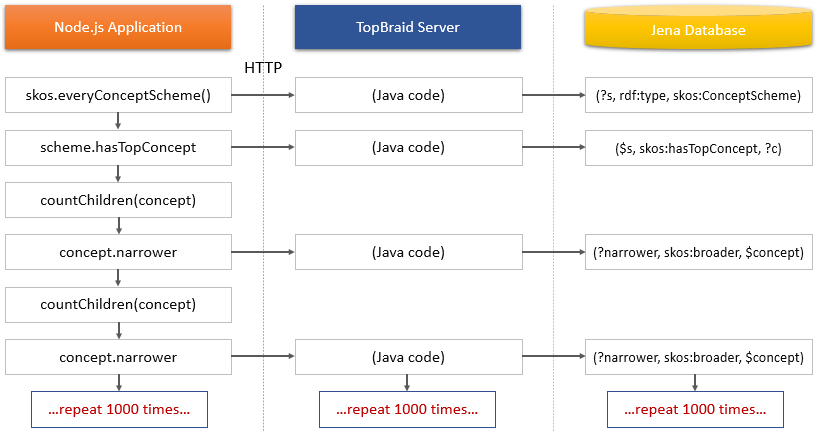
The following subsections outline some strategies on how to minimize the impact of those network requests.
Network Proximity
In order to avoid network latency you will (obviously) want to run your Node.js engine as close to the TopBraid server as possible, for example on the same SaaS environment. To give you some idea, with TopBraid running on localhost, typical calls between Node.js and TopBraid take around 2-3 milliseconds, mostly due to the network and JSON serialization overhead.
Use SPARQL and GraphQL
The next strategy is to minimize the number of server round-trips. In the most extreme case, simply use large SPARQL or GraphQL queries to fetch all data that you need from TopBraid at once, then do the processing on the result sets.
In the example of counting narrower concepts, we could write a SELECT query with a COUNT and then traverse the bindings of the result set:
1console.log('Counting all children...');
2let rs = graph.select(`
3 SELECT ?label (COUNT(?child) AS ?childCount)
4 WHERE {
5 ?scheme a skos:ConceptScheme .
6 ?scheme skos:hasTopConcept ?root .
7 BIND (ui:label(?root) AS ?label)
8 ?child skos:broader+ ?root .
9 } GROUP BY ?label
10`)
11rs.bindings.forEach(b => {
12 console.log(`- ${b.label} has ${b.childCount} narrower concepts`)
13})
This approach works reasonably well if your problem space can be expressed in SPARQL (as in this example). Execution takes around 254 milliseconds. The downside however is that SPARQL isn’t as expressive as JavaScript, and relying on a query string is rather fragile.
Going through GraphQL is a similar alternative as it can produce large JSON objects in a single transaction. However, the expressiveness of GraphQL is even worse than SPARQL because you can basically only ask the queries that the GraphQL schema (based on SHACL shapes) is prepared to handle.
Property value rules
In some cases you could also define an inferred property using sh:values which you can then query with a single transaction such as concept.childCount.
This is often elegant if the new property is of general use.
However, it requires changes to the ontology itself, which is not always possible or desirable.
Installed Functions
The most powerful option by far is to use so-called installed functions. This is a new feature that exists for ADS on Node.js only. The basic idea is that you can define any ADS function in your Node.js application but let it execute on the TopBraid server. Here is how it works, and this program takes less than 200 ms to execute:
1var countChildren = (concept: skos_Concept): number => {
2 let count = 0;
3 concept.narrower.forEach(child => {
4 count += countChildren(child) + 1
5 })
6 return count;
7}
8countChildren = TopBraid.installFunction(countChildren);
9
10console.log('Counting all children...');
11skos.everyConceptScheme().forEach(scheme => {
12 scheme.hasTopConcept.forEach(root => {
13 let childCount = countChildren(root);
14 console.log(`- ${root} has ${childCount} narrower concepts`);
15 })
16})
The only difference between this code and the code in the beginning of the section is the call to TopBraid.installFunction().
This will send the function declaration to the TopBraid server and return a proxy function that has exactly the same signature as the original function, yet executes the function server-side.
This magic is working because both the TopBraid server and the Node.js side are using the same generated API, and therefore almost all code written in installed functions will work unchanged.
In this case, we overwrote the countChildren function.
To make this happen, we declared var countChildren instead of const countChildren.
Needless to say, such installed functions execute in a different scope than the script on Node.js, so they can not access any variables other than those that have been passed in as arguments. Installed functions may however call other installed functions.
Since such installed functions are executing directly on the server’s virtual machine, they can perform arbitrary queries at maximum speed.
You could define a function that collects all relevant data as a JSON object so that the Node.js application doesn’t ever need to query the server again.
In the following variation, a single server call to getChildInfo is made, and the script completes in 80 ms:
1// These functions will execute on the TopBraid server when called
2
3var countChildren = (concept: skos_Concept): number => {
4 let count = 0;
5 concept.narrower.forEach(child => {
6 count += countChildren(child) + 1
7 })
8 return count;
9}
10countChildren = TopBraid.installFunction(countChildren);
11
12var getChildInfo = () => {
13 let results = {};
14 skos.everyConceptScheme().forEach(scheme => {
15 scheme.hasTopConcept.forEach(root => {
16 let childCount = countChildren(root);
17 results[root.toString()] = childCount;
18 });
19 });
20 return results;
21}
22getChildInfo = TopBraid.installFunction(getChildInfo);
23
24
25// This code executes on Node.js only
26
27console.log('Counting all children...');
28let info = getChildInfo();
29for(let label in info) {
30 let childCount = info[label];
31 console.log(`- ${label} has ${childCount} narrower concepts`);
32}
This is much much faster than the original implementation because it requires just two network requests. The implementation of the query logic was shifted to the server:
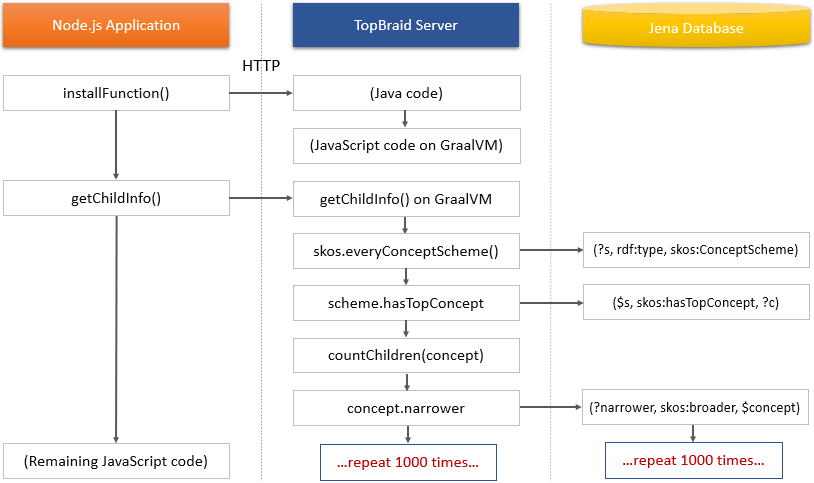
Note that the engine will automatically preserve the object types of the input and output objects.
For example, the input argument concept will be automatically turned back into its original JavaScript class skos_Concept when it executes on the server, and resulting objects would again have the same type as the original function returned.
This mechanism is supported for all subclasses of GraphNode, and nested object or array structures.
In the current implementation, take care to not rename the generated API file, e.g. leave it as in geography_ontology_ads.js.
This is because the mechanism to installed functions relies on the function’s source code (via .toString()), and it needs to remove the module name from certain calls as the ADS server doesn’t have modules.
Another thing to make sure is of course that ontology changes are also updating the generated API files because otherwise the two APIs would diverge and installed functions may no longer work.
But this problem of course applies to any approach that lets client applications run queries.
Write Operations
The generated ADS APIs for Node.js have write access to the graphs, assuming that the authenticated user has the right permissions. Use Administrator to bypass the permission system.
When TopBraid.init() is called, the server will create a session object that uses a so-called DiffGraph to capture any incoming changes before they get written to the database.
This makes it possible, among others, to validate the changes before committing them.
As a performance optimization, the Node.js API will cache all write operations (such as graph.add()) and send them to the server in batches of 100 each.
This removes network latency issues.
However, this cache is flushed whenever a read operation against the graph happens.
You may switch this behavior off if you set readsDoNotDependOnWrites: true in the parameter to TopBraid.init().
This is suitable for cases such as where the script is producing new triples but none of the queries in the loop depends on them.
When write operations are received on the server, the DiffGraph will collect them in memory for the duration of the session.
By default they will then be bundled into a single change when TopBraid.terminate() is called.
However, if the option streaming: true has been set in the TopBraid.init() call, changes will be collected and flushed into the database after the cache overflows (at 100k triples).
This is recommended for very large bulk imports such as spredsheet loaders.
In practice this means that you can freely use calls like g.createCity(...) without having to worry about write performance or how to send the edits to the server in batches.
ADS Features not available on Node.js
The following features are limited to scripts running on the TopBraid server and not directly available on Node.js. You may use some of them via installed functions though.
IOandUploadedFile- this is best handled by Node.js anyway, and there is a huge number of 3rd party libraries available, for example for processing Excel files and connecting to external systems.SQL- there are plenty of alternatives for Node.js.